[더케이뷰티사이언스] ‘연결 인프라 구축(1단계), 데이터 활용 인공지능 개발(2단계), 시스템 및 프로세스 최적화(3단계)를 통한 산업 혁신(4단계)과 사회 발전(5단계)을 이루는 사례들을 집약한 총체’.
전 세계적인 화두인 ‘4차 산업혁명’의 정의와 범위를 인공지능에게 물어보니 이같은 대답이 나왔다.
UNIST(울산과학기술원) 경영공학부 임치현 교수와 이창헌 석・박사통합과정 연구원은 빅데이터 분석과 인공지능 알고리즘으로 4차 산업혁명의 개념과 범위를 밝힌 연구로 관심을 끌었다. 이 연구는 KIST(한국과학기술연구원) 융합연구정책 펠로우십Fellowship 프로그램으로 지원된 연구 중 최우수작인 과학기술정보통신부 장관상을 받았다. 시상식은 2018년 11월 21일 ‘2018 미래융합포럼’에서 진행됐다. 이번 연구결과의 상세한 국문 보고서는 ‘융합연구리뷰(ISSN: 2465-8456) 2018년도 11월호’에서 확인할 수 있다. 보고서명은 ‘4차 산업혁명의 주요 융합 R&D 이슈 파악: 텍스트마이닝을 통한 접근1’이다.
연구배경
2016년 1월에 열린 제46회 다보스포럼에서는 ‘Industry 4.0의 이해’라는 주제로 급속도로 발전하는 정보기술이 인류에 가져올 변화에 대해 논의했다. 전문가들은 사물인터넷, 빅데이터, 인공지능, 블록체인 등에 관한 기술이 ‘4차 산업혁명’을 이뤄낼 것으로, 또 이들 기술을 중심으로 산업・경제・사회 패러다임이 변할 것으로 전망하고 있다.
이 기술들은 ‘사물인터넷과 블록체인의 융합’처럼 서로 융합돼 활용되는 경우가 많다. 따라서 이런 기술들로 실제 가치를 창출하고 국가 경쟁력을 강화하려면 4차 산업혁명 관련 융합 이슈를 상세하게 이해하는 게 필수적이다. 하지만 4차 산업혁명이라는 개념의 포괄성과 모호성 때문에, ‘4차 산업혁명의 범위가 어디까지인지’, ‘4차 산업혁명에서 어떠한 기술들이 중요한지’, ‘관련 응용산업의 구체적 특성은 어떠한지’, 무엇보다 ‘이들 기술이 산업에 응용되기 위한 융합 이슈들이 무엇인지’ 뚜렷하게 파악하기 어려웠다. 몇 사람의 전문가가 4차 산업혁명 관련 모든 정보를 수집하고 소화하기도 현실적으로 매우 어려운 일이다.
이에 본 연구는 텍스트 마이닝text mining 2기술과 비지도학습 알고리즘3에 기반해 4차 산업혁명에 대한 개념과 범위 등을 분석해냈다. 분석 대상은 4차 산업혁명을 명시적으로 언급한 저널의 논문과 언론사의 기사들이며, 프로그램을 통해 자동화된 분석을 수행했다.
연구내용
이번 분석은 ‘4차 산업혁명’을 언급한 국제 저널 논문 660편과 영문 뉴스 기사 3907건을 대상으로 인공지능에게 해석하도록 했다. 논문은 주로 4차 산업혁명 관련 기술적 문제를, 기사는 주로 4차 산업혁명 관련 기술 응용과 사업, 산업, 사회적 이슈들을 다루고 있다.
논문 660편은 2018년 9월 8일까지 학술정보 데이터베이스인 ‘웹 오브 사이언스Web of Science Core Collection’에 등록된 것으로, 이는 데이터 수집 시점까지 ‘4차 산업혁명’을 언급하고 있는 전체에 해당한다. 이들 논문이 게재된 저널은 SCIEScience Citation Index Expanded, SSCISocial Science Citation Index, A&HCIArts&Humanities Citation Index, ECIEmerging Sources Citation Index로 분류된다.
언론기사 3907개는 2018년 9월 17일까지 렉시스넥시스 비즈니스 및 산업 뉴스LexisNexis Business & Industry News의 데이터베이스에 등록된 것으로, 이는 데이터 수집 시점까지 ‘4차 산업혁명’을 언급하고 있는 전체에 해당한다.
연구진은 이 자료에서 텍스트 마이닝한 결과로 4차 산업혁명의 주요 연구 분야와 기술 응용 이슈들을 파악했다. 나아가 주요 연구 분야 간 네트워크 분석, 논문과 기사에 대한 상세 리뷰를 통해 4차 산업혁명의 주요 융합 R&D 이슈를 파악했다. 예를 들어 연구 분야별로 SCIE, SSCI, A&HCI 논문 분포 분석과 내용에 대한 정성적 리뷰에 기반해 ‘공학・과학’과 ‘인문학・사회학’간 융합 R&D 이슈를 파악했다. (그림 1 참조)
파악된 이슈들은 다음과 같은 4차 산업혁명의 5단계에 따라 서술된다. ①단계 ‘연결 인프라 구축’, ②단계 ‘데이터 활용 인공지능 개발’, ③단계 ‘시스템 및 프로세스 최적화’를 통한 ④단계 ‘산업 혁신’과 ⑤단계 ‘사회 발전’을 이루는 사례들을 집약한 총체라고 정의된다. 나아가 본 연구는 기존 국내・외 4차 산업혁명 관련 논의(예: 정부 4차 산업혁명위원회에서의 논의)와 비교하며, 4차 산업혁명 시대 융합 촉진을 위한 방법으로 몇 가지 융합연구정책 방향을 제안했다. 즉 4차 산업혁명 실현을 위한 다섯 단계별 19개의 주요 연구 분야도 분류할 수 있었다. (그림2 참조)
연구결과물은 국・내외 관련 논의와 일관적・상호 보완적으로 나타났으며, 이는 본 연구가 취한 ‘문서 빅데이터 분석 기반의 접근’이 다양한 분야 다수 전문가들의 의견을 종합한 결과의 근거나 보완자료가 될 매우 효율적인 접근임을 나타낸다. 이창헌 연구원은 “이번 연구를 통해 4차 산업혁명의 핵심을 요약하는 특징을 여섯 가지6C로 정리했다”며 “사람・사물・조직의 연결Connection과 데이터 수집Collection, 소통Communications, 인공지능 연산Computation, 시스템과 프로세스 제어Control, 가치 창출Creation이다”고 설명했다. (그림3 참조)
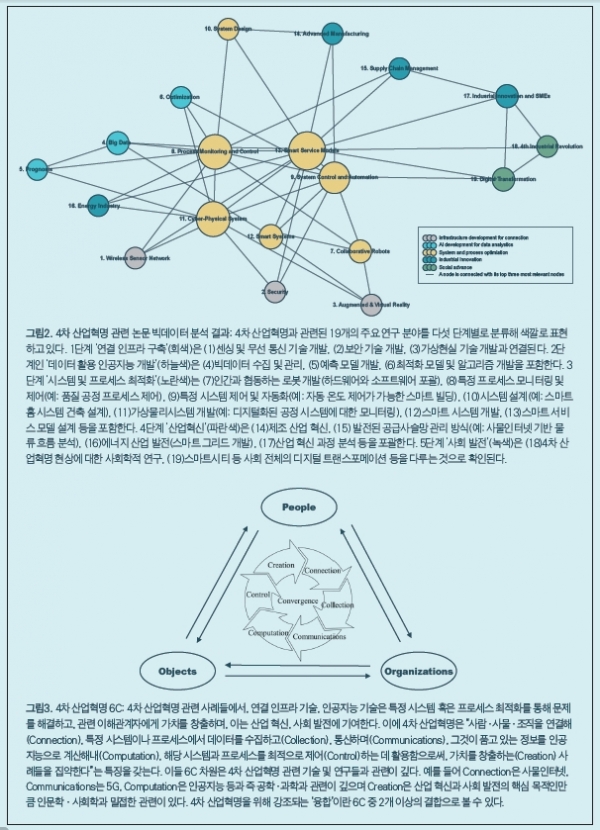
4차 산업혁명을 위해 강조되는 ‘융합’이란 여섯 특징 중 2개 이상의 결합으로 볼 수 있다. 연구진은 또 인공지능의 논문과 기사 해석 결과들을 활용해 ‘4차 산업혁명 실현을 위한 주요 융합 연구개발R&D 주제 28개’도 발굴했다. 28개 주제들은 4차 산업혁명의 다섯 단계별로 분류된다. (표1 참조) 이 내용은 4차 산업혁명과 관련한 융합 R&D를 촉진하는 데 기여할 전망이다.
기대효과
본 연구는 4차 산업혁명의 개념과 범위를 명확하게 잡는 데 기여하며, 관련 융합 R&D를 촉진할 것이다. 구체적으로 본 연구는 4차 산업혁명을 직접적으로 언급하는 문헌과 뉴스 데이터 대부분을 분석했다는 점에서 ‘포괄성’을 가진다.
또 분석 방법이 정량적이라는 점에서 ‘객관성’을 가진다. 정량적 분석의 한계를 극복하기 위해 연구진은 데이터를 직접 정성적으로 리뷰하고 관련 문헌을 참조하고자 노력했다.
최종적으로 도출된 융합 R&D 이슈는 통합적 접근으로 도출됐으며, 4차 산업혁명의 다섯 단계에 따라 체계적으로 구조화되고 서술됐다는 데 의의를 가진다. 이번 연구로 도출된 28개 융합 R&D 이슈가 완전한exhaustive 목록은 아니며, 추가 연구로 정제, 확장돼야 한다.
연구진은 이번 결과가 4차 산업혁명의 이해와 촉진을 위한 주요 지침reference으로 활용될 수 있으리라 생각한다. 또 이 자료가 융합을 통한 국내 기업・산업 경쟁력 강화에, 사회 발전에, 정부 및 국내 학계가 4차 산업혁명 관련 분야의 국제적 우위를 선점하는 데 기여하길 희망한다.

임치현 교수는 “인공지능의 4차 산업혁명 해석 결과는 기존 국내・외 4차 산업혁명 관련 논의와 비교했을 때 일관성이 있었고, 상호보완적으로 활용 가능한 것으로 나타났다”며 “이번 연구는 지식 발전을 위한 인간과 인공지능의 협력 가능성을 보여준 사례”라고 연구 의미를 밝혔다.
이어 “많은 사람들이 4차 산업혁명을 말하지만, 이것이 무엇인지 또 앞으로 4차 산업혁명에 대응하려면 어떻게 해야 하는지 명확하지 않은 상황”이라며 “이번 연구는 이런 사회적 갈증을 해소하고자 시도됐고 추후 더욱 포괄적이고 정교한 데이터 분석을 통해 우리나라의 산업 및 사회 발전을 위한 시사점을 정리하고 싶다”고 덧붙였다.
1. 4차 산업혁명의 주요 융합 R&D 이슈 파악: 텍스트마이닝을 통한 접근’ 보고서 바로가기:
https://crpc.kist.re.kr/common/attachfile/attachfileNumPdf.do?boardNo=00006686&boardInfoNo=0023&rowNo=1
2. 텍스트 마이닝(text mining):말 그대로 글(텍스트)을 캐낸다(마이닝은 ‘mining’으로 ‘(광산을)채굴하다’라는 뜻)는 의미. 문서 내 단어의 중요도 값이나 단어 간 통계적 관계 등을 파악해 유의미한 정보를 추출하는 작업이다.
3. 비지도 학습(Unsupervised Learning): 기계학습(Machine Learning)의 일종으로, 데이터가 어떻게 구성됐는지 알아내는 문제의 범주에 속한다. 이 방법은 지도 학습(Supervised Learning) 혹은 강화 학습(Reinforcement Learning)과는 달리 지도를 위한 데이터 혹은 목적식이 주어지지 않는다.